Noah Brier | May 15, 2024
The AI Ratings Edition
On chess, chatbots, and stakes.
Noah here. When we talk about a chess player being a Grandmaster, we're really referring to their "Elo rating." This system, named after physics professor and chess player Arpad Elo, was designed not only to compare two players facing off but also players who might never play against each other.
The basic concept of Elo's scoring is pretty straightforward: each player "wagers" a number of points based on their experience, and the winner gets some of those points depending on how likely they were to win. For example, if two inexperienced but equally matched players face off in international adult play, twenty points are on the line. With an equal chance of winning, the winner’s rating goes up by 10 points, and the loser’s rating goes down by 10. If the match is more lopsided, the points will be distributed accordingly. For instance, if a 1200 player defeats a 2000 player, they would get all 20 available points since the odds of beating an opponent ranked 800 points above you is roughly zero.
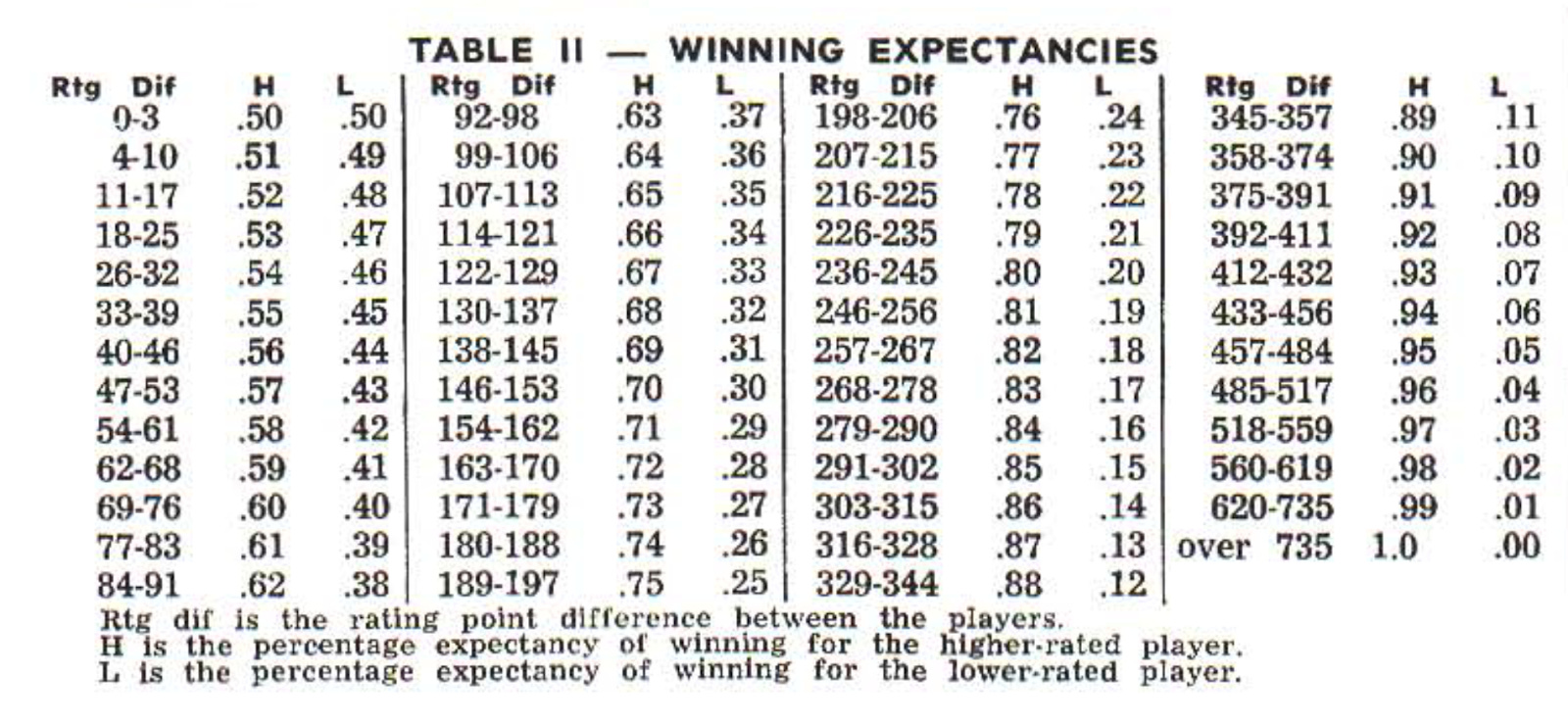
The system has been solid enough that chess federations have used some version of it for over seventy years.
Why is this interesting?
Today, AI models are being pitted against each other and evaluated in much the same way. Outside of ChatGPT, one of the hottest properties in AI is the LMSYS Chatbot Arena. Ask anyone who spends a lot of time playing with large language models (LLMs) what their go-to evaluation is, and they’ll send you to chat.lmsys.org.